BBR(Bottleneck Bandwidth and Round-trip propagation time)是Google于2016年提出的一个新的拥塞控制算法,给拥塞控制这一领域提供了一个全新的思路。
传统的拥塞控制算法思路是基于事件(ack,丢包等)来进行发送速率(cwnd)决策的。而BBR则通过测量网络中带宽与RTT两个变量来进行发送速率与方法的决策。
Why we need BBR
先说传统的拥塞控制算法的基本情况,传统的CC(congestion control)算法是基于事件反馈来进行决策的。如经典的TCP Reno:在接受到一个成功的ACK时增大cwnd拥塞窗口,在发现丢包时(通常为接受到3个冗余ACK/Duplicate ACKs)执行快速重传与降低cwnd(congestion window)。因此一个理想的TCP Reno算法执行过程为下图(Presentation by Geoff Huston at APRICOT 2018.),为一个锯齿形。
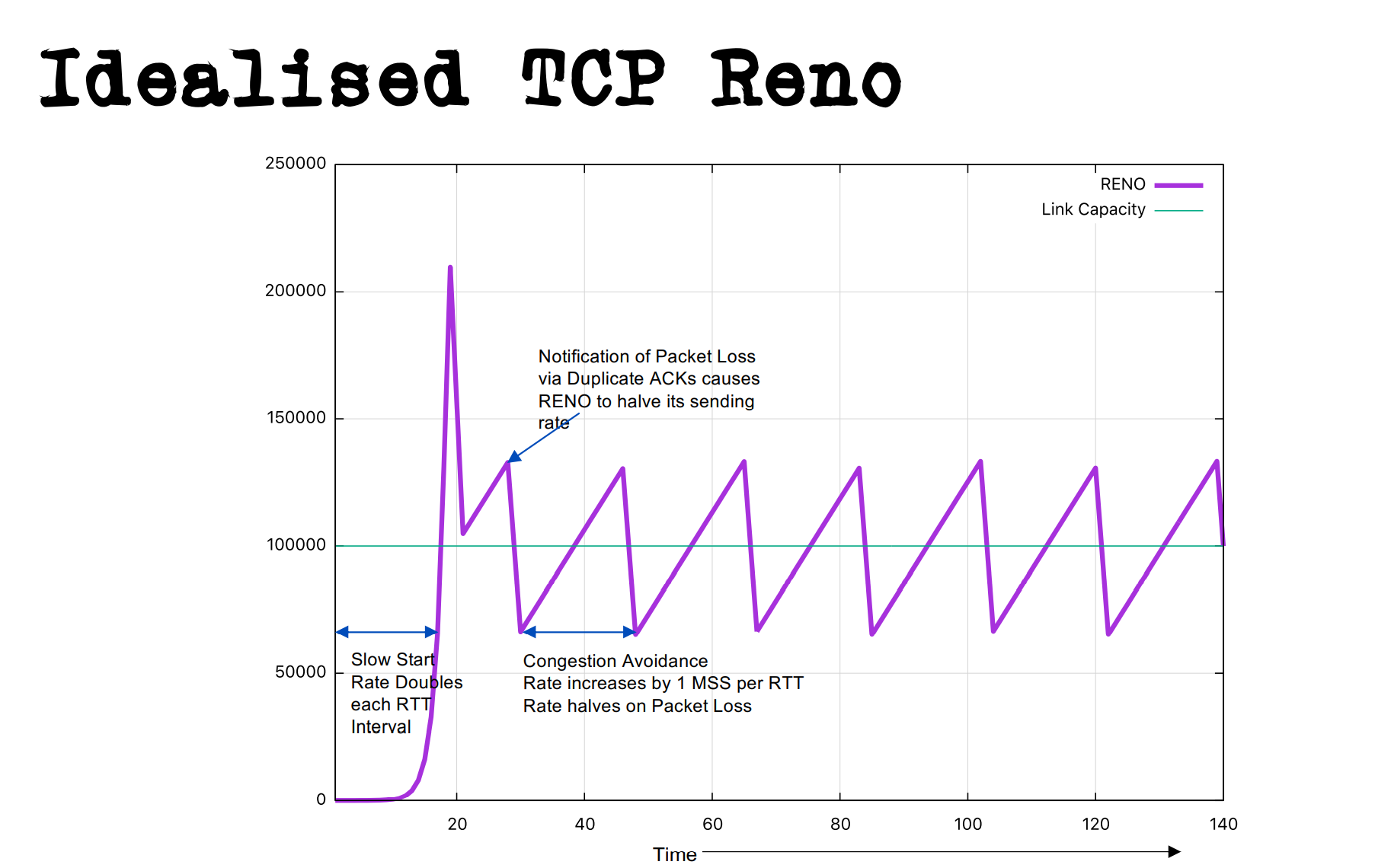
而其后对其进行改进的TCP Cubic,也仅是在增大cwnd是使用非线性函数(cubic函数)而非Reno的线性函数(一般是+1)。因此一个理想的TCP Cubic算法执行过程为下图(Presentation by Geoff Huston at APRICOT 2018.)可以看到与TCP Reno比仍然是一个“锯齿”形的。
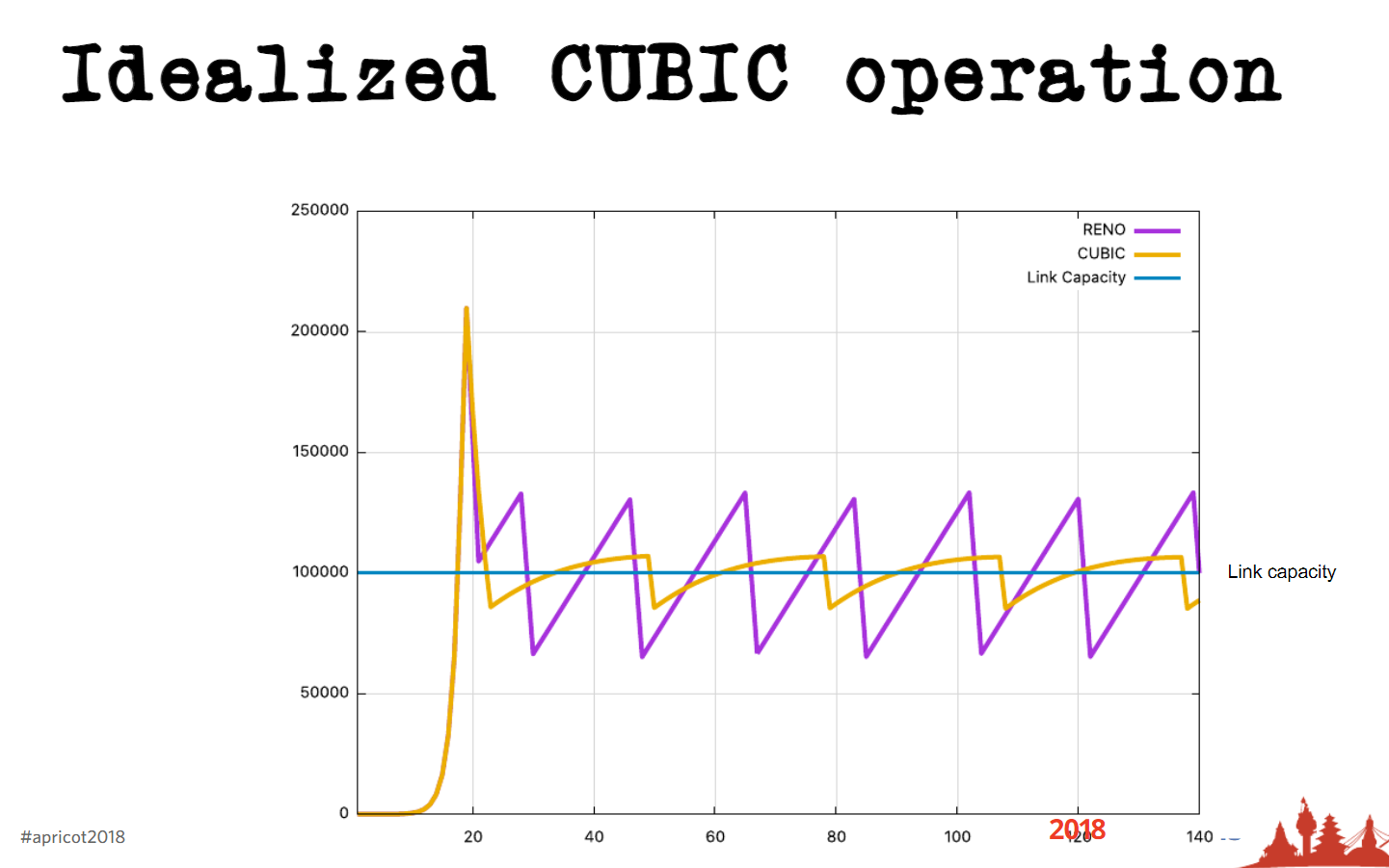
那么,这种传统的拥塞控制算法会面临哪些不足呢?Google的BBR论文的论述逻辑为:关注bottleneck!
TCP流量的传输中bottleneck是十分重要的,它不仅决定的网络中的最大发送速率,同时也是队列持续产生的地方(相同入队速率,出队速率最小的地方最容易发送队列堆积)。
当bottleneck的buffer大时,loss-based cc 会倾向于打满它,造成bufferbloat,使得buffer等待时间变长,RTT增大(现在中间节点的buffer相比于之前变得相当大,使得在buffer中的延迟变得重要起来);当bottleneck的buffer小时,loss-based cc 则会因为浅buffer造成的频繁丢包而使得大多数时间都处在一个较低的发送速率(锯齿形上升时很快就遇到丢包造成cwnd减少)。
接着说回BBR,BBR则采用了另一种不同的思路,即采用RTprop (round-trip propagation time)与BtlBw (bottleneck bandwidth) 来决定传输的速率。见下面这个大家在许多地方都见到过的图:
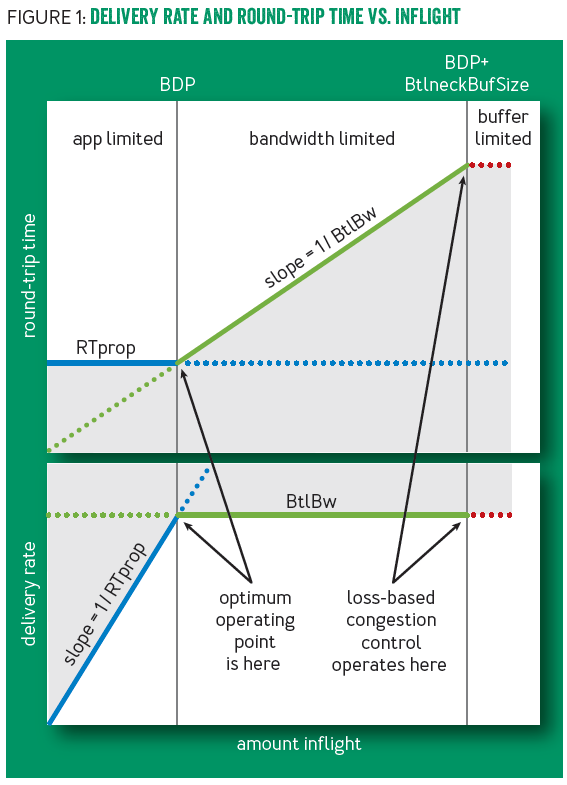
BBR的目标,就是去接近上图中的最优点(optimum operating point)。此时传输过程中的正在发送的inflight报文数量正好匹配bottleneck的处理速率(inflight报文数少了会造成带宽浪费,多了会超过bottleneck处理速率造成buffer堆积使得RTT增大)。该最优点对应的传送报文数 inflight =BDP* (bandwidth-delay product). 此处inflight为发送但未接收到对应ACKs的报文数
BDP = BtlBw × RTprop
RTprop = 一段时间内(数十秒)的minRTT
BtlBw = 一段时间窗口(6-10RTTs)内最大的deliverayRate(Δdelivered/Δt)
因此,BBR算法的工作流程就很清晰明了了:通过测量链路中的BtlBw与RTprop来计算BDP,再通过调整发送端发送速率使得inflight的报文等于BDP.
BBR Architecture
知道了BBR算法的设计思路后,在实现的过程中必然会遇到这两个问题:如何测量当前链路的BDP与如何调整发送速率使得inflight packets匹配BDP。针对第一个问题,BBR与各类CC类似,在接收到报文ACK时统计其 RTT 与 deliveray rate ,并以此更新RTprop与BtlBw. 而对于第二个问题,BBR选择采用cwnd_gain与pacing机制一同来调整发送速率,具体代码如下:
function send(packet)
bdp = BtlBwFilter.currentMax RTpropFilter.currentMin // BDP 估计
if (inflight >= cwnd_gain*bdp) // 可以看作是传统CC 中的 cwnd
// wait for ack or timeout
return
if (now >= nextSendTime)
packet = nextPacketToSend()
if (! packet)
app_limited_until = inflight
return
packet.app_limited = (app_limited_until > 0)
packet.sendtime = now
packet.delivered = delivered
packet.delivered_time = delivered_time
ship(packet)
nextSendTime = now + packet.size / (pacing_gain * BtlBwFilter.currentMax)
timerCallbackAt(send, nextSendTime)
可以看到BBR发送的目标也是保证inflight的报文不会超过当前链路的BDP,因此每个packet进行发送时都会进行处理。
当有新的报文需要发送时,BBR仅会当inflight的报文小于BDPcwnd_gain(比例系数,后面会详谈)进行发送。同时发送动作也是由pacing机制控制着,目的是防止突发的发送速率增高超过bottleneck的处理速率造成排队,因此pacing速率也是基于当前带宽bandwidth的。BBR pacing机制具体来说为只有 now >= nextSendTime 时才执行发包动作,且将数据包在时机尺度上尽量平均送出(nextSendTime = now + packet.size / (pacing_gain * BtlBwFilter.currentMax)) 此处pacing_gain为控制pacing rate的增益系数,数值越大则数据包的发送越密集,为1时则是等待上个数据包传输完成后再发送。
BDP 的估计
看完了数据包发送时的处理流程,下面就该介绍BBR最为核心的部分:BDP的估计。
其实通过带宽(BtlBw)与延时(RTprop)来判断链路状态的想法很早就有了。上面optimum operating point的图就是基于Leonard Kleinrock 的工作,其于1979年论述了该operating point就是拥塞控制算法能达到的最佳的点。但为何直到最近才随着BBR得到大规模的应用呢?原有是同时代Jeffrey M. Jaffe 证明了使用某种算法去收敛到该operating point是不可能的(RTprop的测量需要传输链路上没有排队,而没有排队就无法判断当前发送速率是否达到了瓶颈带宽BtlBw,因此二者无法同时测得),因此在该方向上的研究一直没能掀起什么大的风浪。
再说回BBR,既然使用某种算法去收敛到最优点是不可能的,那么BBR基于带宽(BtlBw)与延时(RTprop)计算得来的BDP = BtlBw*RTprop是怎么保证能够尽可能接近该最优点optimum operating point的呢?
BBR的做法是通过探测一段时间内的网络状况来去估计网络的RTTprop与BtlBw:
Although it is impossible to disambiguate any single measurement, a connection’s behavior over time tells a clearer story,
BBR的做法是设计两个不同的状态去分别估计RTTprop与BtlBw。这样设计的合理性是网络层路由选择算法更新传输路径(OSPF中链路状态变化或周期触发, etc.)的变化频率相较于cc决策来说低很多(分钟/秒级别 vs RTT毫秒级别)。这就意味这在cc的很多轮cwnd决策过程中,下边网络层的传输路径是不变的,同时报文在上面传输的RTTprop也是不变的。
既然RTTprop变化频率很低,因此BBR大部分时间都处在预测BtlBw的状态中(probeBW)。由于当达到最大瓶颈带宽/BtlBw时,再次增加发送带宽会造成排队使得RTT开始增长(隐含前提是这段时间内RTTprop不变),因此在处于probeBW状态时BBR通过周期性上探发送带宽(配合以带宽下降用以排空上探造成的堆积的队列),若上探到某一带宽后继续上探时RTT开始增长,就意味着该带宽就是BtlBw。
而对于RTTprop的估计,若一段时间(10s)内没有接收到小于等于RTTprop的RTT的ack,就认为传输路径可能发生了变化,进入probeRTT状态去排空队列并重新计算RTTprop。(在与尝试打满buffer的loss-based流共存时如何得到可信的RTTprop估计是BBR设计里最容易被挑战的一点,之后的文章再详谈)
BBR States
再说回到BBR的具体工作流程,下面就是BBR算法的状态转移情况(copy from: github.com/google tcp_bbr2.c)
Here is a state transition diagram for BBR:
|
V
+---> STARTUP ----+
| | |
| V |
| DRAIN ----+
| | |
| V |
+---> PROBE_BW ----+
| ^ | |
| | | |
| +----+ |
| |
+---- PROBE_RTT <--+
需要注意的是:BBR 的各个状态仅仅决定pacing_gain 与 cwnd_gain 的取值。各个状态的取值为:
STARTUP: pacing_gain 2.89,cwnd_gain 2.89
DRAIN: pacing_gain 0.35, cwnd_gain 2.89
PROPEBW:pacing_gain [5/4, 3/4, 1, 1, 1, 1], cwnd_gain 2
PROPERTT: pacing_gain 1 cwnd_gain 1(配合以cwnd固定大小=4)
结合上边的发送过程
if (inflight >= cwnd_gain*bdp)
// wait for ack or timeout
return
'''
nextSendTime = now + packet.size / (pacing_gain*BtlBwFilter.currentMax)
cwnd 决定可以往链路中发送的容量,数值越大代表着可以往链路中发送的报文越多;
pacing_gain为控制pacing rate的增益系数,数值越大则数据包的发送越密集 (burst sending).
可以看到,BBR 对 inflight packets的调整是通过调整pacing速率来进行的。cwnd_gain 的变化基本是为了配合pacing_gain的变化而调整。
BBR 状态转移过程
对于状态变化的具体情况:BBR首先会从STARTUP状态开始,并尽快的提升其的发送速率(指数级)
Startup implements a binary search for BtlBw by using a gain of 2/ln(2) = 2.89 to double the sending rate while delivery rate is increasing.
This discovers BtlBw in (BDP) RTTs but creates up to 2BDP excess queue in the process.
此时 pacing_gain = cwnd_gain = 2/ln(2) = 2.89. 发送速率2倍于BDP.
当BBR判断传输链路变满时 (通常STARTUP状态下BtlBw三轮涨幅不超过 25%),可能会在传输链路上堆积up to 2BDP excess queue in the process (2倍往上递增),因此需要进入DRAIN排空阶段来排空这些堆积,直到 inflight 降到 BDP 为止。
The pacing gain of 1/high_gain in BBR_DRAIN is calculated to typically drain the queue created in BBR_STARTUP in a single round
进入DRAIN阶段后:
pacing_gain = 1/high_gain = 1/(2/ln(2)) = 0.35; // 选择降低发包密度(pacing slow)
cwnd_gain = bbr_high_gain = 2.89. // 此时BBR选择维持 cwnd
可以看到 BBR 在 Drain 状态选择维持 cwnd 大小而降低 pacing rate,通过pacing机制降低发包的速率以此来减少 inflight 的报文。当 inflight packets <= BDP 时,BBR 进入稳定阶段(steady-state),这个阶段只会在PROBE_BW与PROBE_RTT之间切换。
BBR 会首先从 Drain 切换到 PROBE_BW 状态,一个BBR流大部分时间都是重复着PROBE_BW这一状态去探测传输管道的可用带宽。此时其通过 gain cycling 的机制使得pacing_gain顺序的在[5/4,3/4,1,1,1,1,1,1]中进行选择。而pacing_gain 是否进入下一个值则依赖于inflight 报文是否仍处于当前值期望的状态,如pacing_gain=5/4时,BBR上探BtlBw,若此时 deliveryRate 仍增长(Δdelivered增大且此时Δt不相应变大,代表bottleneck还未堆积队列造成RTT增长),则pacing_gain 仍等于 5/4,否则则进入下一个取值 pacing_gain = 3/4 排空inflight报文。
同时,如果在10s内未出现相等于BBR的min_RTT的值(或出现小于RTTprop的值),BBR就认为链路中的传播时延RTTprop发生了变化,进入PROBE_RTT状态去探测最新的RTTprop。方法是去将inflight的报文降到最低,此时设置cwnd=4,当inflight <= 4时开始重新探测min_RTT来作为RTTprop的值。在维持PROBE_RTT最少200ms后,BBR会根据管道是否被打满去选择进入PROBE_BW或STARTUP状态。
一个典型的 BBR 流开始周期可以参考下图:
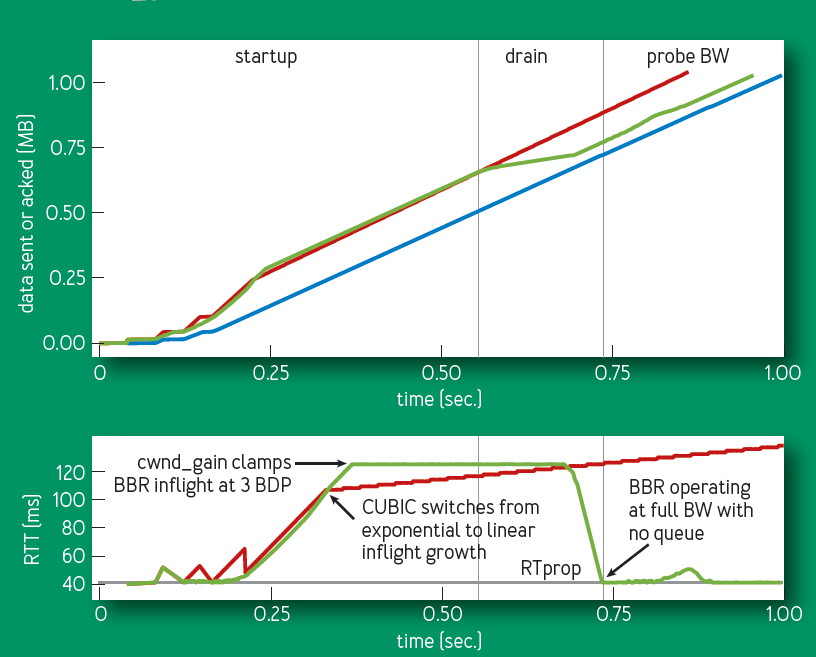
Red: CUBIC sender; Grean: BBR sender; Blue: ACK
BBR 多流
多个 TCP 流场景下可以再细分为两种情况:多条BBR流与多条混合的流。
对于多条BBR流的场景,公平性的保证是依靠BBR处于大部分处于的PROBE_BW状态的周期性带宽让出与PROB_RTT状态下流发送速率降低到最低限度来保证的。
具体来说,PROBE_BW状态下pacing_gain会周期性的到达3/4=0.75的值,这将降低BBR sender发送报文的速率,以将带宽让渡给其他流。但这里需要注意的是,pacing_gain取0.75时意味着其在上一个周期的pacing_gain值为5/4=1.25(密集发包),因此其上一个周期内上探带宽的动作其实也挤占了更多的流。当前周期让渡出的带宽目的是为了排空上探带宽时造成的堆积报文,并不能完全保证公平性。
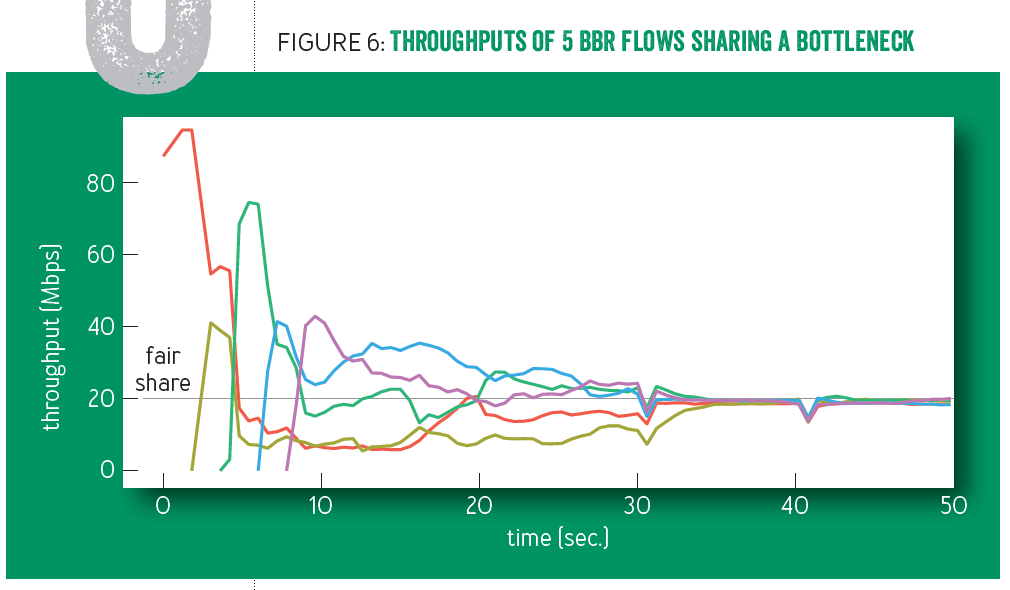
因此公平性的保证主要的是靠large flows进入PROBE_RTT状态,将发送窗口降低到4来极大地降低网络中传输地数据量,而网络中传输数据的大量降低通常会导致排队时延减低,这样其他BBR流就会探测到更低的RTT值,并且也一同进入PROBE_RTT状态,发送窗口设为4让出带宽,使得传输时延进一步降低,其他流也探测到了更低的RTT值... 以此让这些BBR流一齐进入PROBE_RTT状态,并在PROBE_RTT状态结束后一齐依据BBR算法探测BDP从而决定发送带宽(下图30sec时一齐进入PROBE_RTT带宽降低,之后一齐上探从而使得带宽公平利用)。这种分布式的协助机制是BBR流之间保证公平性的关键。
然而,对于非BBR流之间的公平性保证,效果就不一定好了。从上段可以看出,不同BBR流分布式的配合协助机制生效的前提是:large BBR flows会周期性进入PROBE_RTT状态让出带宽,并且让出带宽这个动作造成的延时下降使得其他的flows探测到更低的RTT。
但在面对其他类型的flows时(例如loss-based 的 Reno/Cubic),若占据大量带宽的是 loss-based flow,那么周期性进入低发送速率状态这一前提就不存在了。只有在碰上丢包事件时才会降低发送速率,而从前面的介绍中可以判断此时bottleneck的排队情况已经很严重了(发送丢包),已经影响到时延敏感的flow的体验。同时,BBR流通过探测到新的minRTT值来进入同步PROBE_RTT状态再一齐上探保证公平性时,其他不基于RTT作发送判断的流则不会下调其发送带宽,去抢占了更多BBR flows出让的带宽,这就使得BBR的公平性保证受到了挑战。