从TCP/IP协议诞生之日起到今天,拥塞控制问题已经被研究了几十年了,但仍然是一个非常有挑战性的领域,近年来也有许多新的拥塞控制模型的设计被提出,例如Google BBR 与 copa [1].
同时,随着近年来的机器学习热潮,将机器学习的高泛化优势引入CC (congestion control) 的想法也逐渐受到关注,sigcomm20 的 orca [2] 就是一个例子。
那么,在介绍Machine Learing on CC 之前,我们先来谈一谈为什么 ML 可以对CC领域有所帮助。
Why we need learning-based CC
[3] 中提到,由于当前新网络场景与环境的剧烈浮现(数据中心,5G,卫星网络,etc.),使得设计出能够在这些不同场景下都能良好工作的CC机制愈发具有挑战性(效率,公平, etc.)。
同时要注意,在面对复杂多变的网络环境时,一个CC算法往往会会变成 jack of all trades,master of none(杂而不精)或只专注于某类场景 [2]. 例如BBR算法是面对bottleneck buffer bloat的问题而设计,因此在面对浅buffer的场景时,上探带宽引入排队时延的部分在浅buffer场景下就很容易发生丢包而影响最终效果,这种也被称之为 laser-focused solutions.
这也的确是一个必须现实中要面对的问题:CC在建模设计时,都是基于设计者自身思考得出的某种网络假设与建模的。但网络环境的复杂多变决定了设计者在设计CC机制时无法完全覆盖住所有的网络假设与状况。那么这些 modle_based CC which making decidions by predetermined rules 在面对复杂多变的网络状况时,在没有后续人为调整的情况下,是很难一直保持高性能的传输的。
What is learning-based CC
与传统的基于模型的预先决定好规则的CC不同,learning-based CC 的决策制定是基于实时的网络状态的。
这里的 learning-based CC 可以再继续细分为两个部分:最优化性能CC(performance-oriented CC) 与 data-driven/Machine-learning CC. 其中 performance-oriented CC 与 传统CC的边界十分模糊,ML-CC则是比较受到当前CC领域的关注。
performance-oriented CC:
这里需要注意,performance-oriented CC 与 传统CC的界限十分模糊,因为这些CC机制的决策规则都是提前就人为决定好了的,并且传统CC其实也是实时决策的。若真的要划分出区别的话,则只不过是传统CC机制们是基于事件而非基于状态,例如lose-based CC 基于丢包这一事件修改cwnd,BBR在PROBE_BW状态下上探带宽时依据deliveryRate是否依然保持增长决定下一周期的pacing_gain,根据是否出现 RTT 测量值与 min_RTT 的对比情况判断是否要进入PROBE_RTT状态,这些都是CC基于预先设定好的规则根据网络中是否有目标事件的发生而做出各个传输决策。
而performance-oriented CC 不同,其则是根据预先设定好的模型,通过测量网络中的实时状态(values而非阶梯型的event)来决定下一步的决策。
这里举出两个比较经典的performance-oriented CC 算法:Copa [4] 与 PCC [5]
- Copa: 决策思路queuing-delay 来计算target_sending_rate. 其最优化目标为:maximize , , where λ = throughput, d = propagation delay.
论文作者在特定的报文到来的模型假设下,便可以求解出在最大化优化目标U时,特定d下的target_sending_rate λ : 。并以此为依据将当前sending_rate 往target_sending_rate方向接近。 - PCC: PCC也是根据预先设定的计算函数,将当前的网络状态(sending rate, loss rate, RTT)计算出一个 Utility 值,再根据计算出的 Utility值 u 来决定下一步的发送速率。
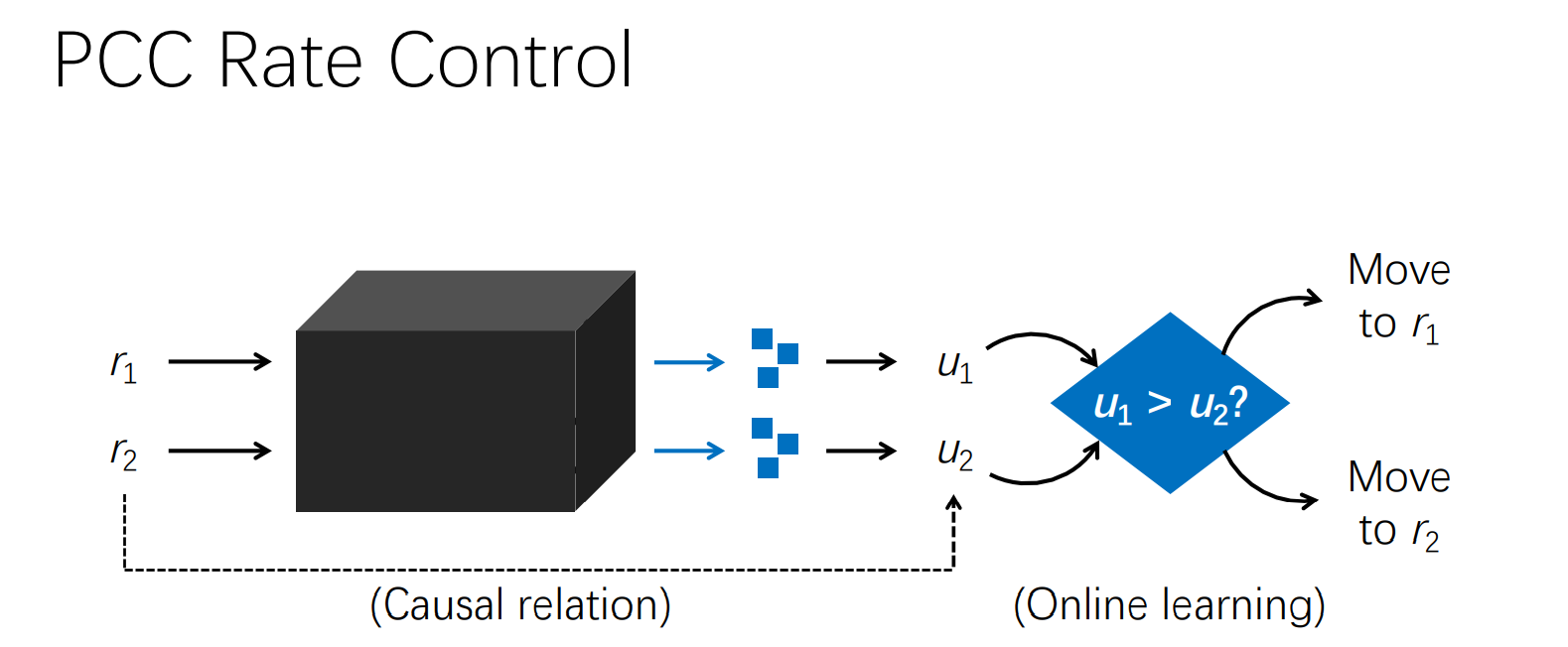
具体来说:
For each pair, PCC attempts a slightly higher rate r(1+ε) and slightly lower rate r(1 − ε). PCC gets two utility measure ments U+ ,U− corresponding to r(1 + ε),r(1 − ε) re spectively. If the higher rate consistently has higher >utility (U+ > U−), then PCC adjusts its sending rate to r new = r(1+ε);
但需要注意的是,performance-oriented CC 的决策模型依旧是人为预先设置好的(最优化函数建模, etc.)并基于此规则对实时网络状态做出反应,做出发送决策调整。
而下面将要介绍的 data-driven/Machine-learning CC 则不相同。
Machine Learning CC
ML CC 与之前的 CC 算法最大的不同就是这些算法会依据数据来去更新其模型的参数设置,而不是去依赖认为提前设置好的模型参数,这也是这类CC算法被称之为 data-driven CC 的原因。
具体来说,Machine Learning CC 可以被划分为三类:supervised/unsupervised learning CC 与 Reinforce learning CC
Supervised/Unsupervised learning CC
机器学习领域中经典的监督学习与无监督学习在 CC 领域内的相关应用由来已久,早在1999年,就有研究人员将监督学习运用在“拥塞丢包”的原因探究上 [6], 通过报文的 inter-arrival times 用以区分丢包是由于wireless loss 还是 congestion loss. 但对于在 CC 机制本身的设计方面则应用较少(近几年优秀会议上基本没出现)。根本原因还是因为监督/无监督学习是离线训练的机制,模型参数的设定是基于离线的训练数据集训练而得来的。虽然可能在测试集上表现优异,但还是跟之前提到过的 traditional CC 的不足一样,无法适应复杂多变的网络环境,一旦真实网络中出现未在训练集中的网络状况时,基于监督/无监督学习的CC机制是无法一直保证高性能的传输的。
Reinforce learning CC
由于传统的监督/无监督的机器学习方法学习在面对复杂多变的网络环境时不能仅依据预先训练好的模型做出足够动态变化的反应以应对,强化学习 Reinforce learning CC 便受到了非常多的关注。
强化学习方法的优势在于:他不仅实时观测实时的网络状态,并且还会对此做出反应,在每一轮内并通过最大化其内 reward function 期望来利用这些实时的网络状态来调整模型参数,使之能对网络的变化做出有效反应。这方面的经典工作就是sigcomm20的 Orca [2]
Orca: Classic Meets Modern
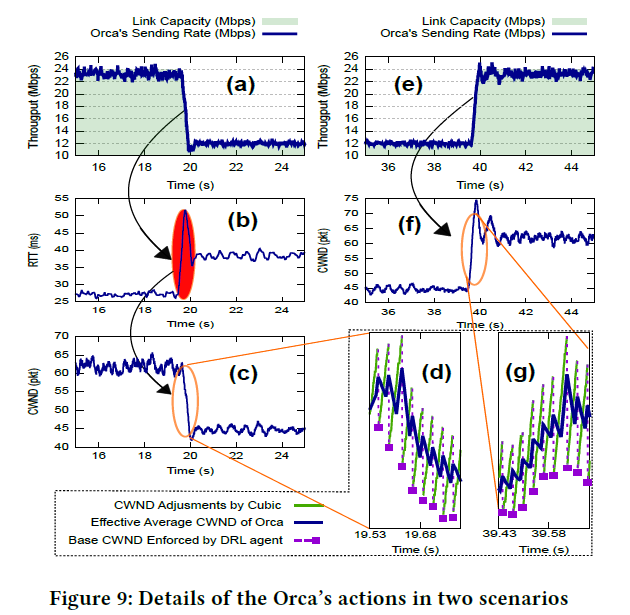
在Orca中,其提出了Machine Learning CC所面对的三个挑战:1- Problem with unseen network scenarios; 2- Convergence issue; 3- Overhead。这些都是挡在ML CC 走向更大舞台所面临的障碍。而Orca创新性的通过“分层”的思想,将 DRL ( Deep Reinforce learning) CC 与 traditional CC 相结合,由 Deep reinforce learning to decide coarse-grain cwnd as based cwnd. 下层的传统TCP CC (Cubic) 再在该based-cwnd基础上进行细粒度的cwnd调整,这样就很大程度上解决的之前提到的三个挑战:
- Problem with unseen network scenarios:
通过强化学习与深度学习相结合,并发挥深度学习从原始数据中提炼高维信息的优势,可以 "utilize its potentials and capabilities to learn from actual raw input data without relying on preprocessing or handcraft engineering" - Convergence issue:
对于收敛性的保证,通过往DRL的数据结果 (based cwnd) 故意加上些扰动,由下层的传统TCP Cubic CC 作后备,来提高Orca的收敛性表现。 - Overhead
由于其创新的分层思想,DRL只决定粗时间粒度上的cwnd,下层细时间颗粒度的cwnd调整由Linux内核自带的Cubic执行,客观上降低了计算开销,论文中测试其cpu utilization为不到10%,大幅优于其他learing-based CC 算法。
Orca工作时的流程可以参考下图:
Next Step
当然,现如今 ML on CC 还有相当大的一段距离要走,其中一个相当重要的问题需要解决,那就是其可解释性。一个CC 机制在实际应用时,必须要考虑其收敛性与公平性,而ML CC 可解释性的缺乏使得我们很难去分析其收敛性质与跟其他流竞争时的表现。
sigcomm20 的工作 Metis [7] 给了我们一个思路,将DL-based network systems 解释为决策树与超图 (hypergraphs) 的形式来给管理员们分析DL-based network systems 的各个性能表现提供了帮助。但如何将ML CC 应用到实际,像BBR那样给网络传输性能带来真正帮助,还仍有相当多的工作值得我们去发掘。
参考资料:
[1]"Copa: Practical delay-based congestion control for the internet." 15th {USENIX} ({NSDI} 18). 2018.
[2] "Classic meets modern: A pragmatic learning-based congestion control for the Internet."
[3] When Machine Learning Meets Congestion Control: A Survey and Comparison
[4] "Copa: Practical delay-based congestion control for the internet." ({NSDI} 18). 2018.
[5] "{PCC}: Re-architecting congestion control for consistent high performance." ({NSDI} 15). 2015.
[6] "Discriminating congestion losses from wireless losses using inter-arrival times at the receiver," 1999
[7] Interpreting Deep Learning-Based Networking Systems. (SIGCOMM '20).